
I've been determining my running FTP since 2018. Back then I'd bought myself a Stryd, the one with the wireless charging pad you just pop it onto. It didn't have "Air Power" yet, but it was no longer the prototype you had to strap around your chest either. I've been running with power ever since.

My first Stryd on the shoe, September 2019. Half a childhood ago.
After 8 years of running with power and the feel I've developed for it over time, I'm now able to estimate my FTP off the top of my head. The prerequisite, though, is that I've done a somewhat intense run and am reasonably fit. Otherwise the reference is missing and my body feel isn't calibrated.
My own FTP estimate
After a longer break from serious training, I've been building back up for 2 months now. Yesterday I did a few threshold intervals: 3 x 6 minutes at roughly 85-88% of maximum heart rate, deliberately controlled, no all-out effort.
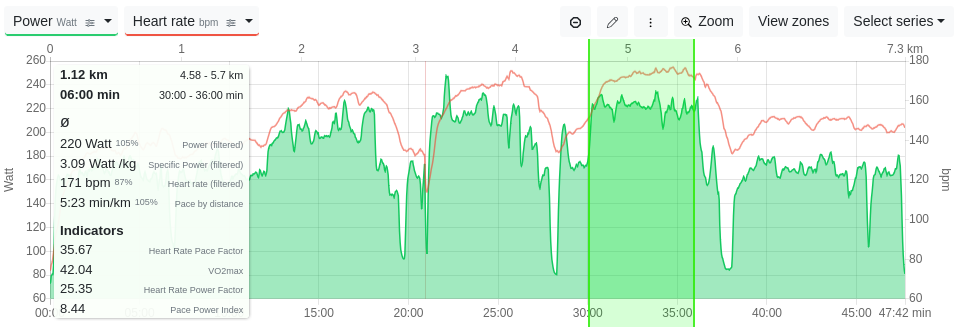
The three threshold intervals from my run in Tredict with power output and heart rate in the time series.
To be honest, I executed the intervals rather sloppily. The first was actually too slow, the second too uneven, but the third was decent. You might know the feeling.
So here's my personal FTP estimate, based on yesterday's run with 3 x 6-minute threshold intervals. I reckon my current FTP sits at around 225 watts. That's the power I could sustain consistently for one hour.
Now let's see what the AI models have to say when they look at yesterday's run and a few runs before that.
And you'll have to trust me on this, I promise: I made my own estimate before running the tests with the models.
The test: one prompt, six models
All six AI models were given access to my training data via the Tredict MCP server or the official Tredict ChatGPT app. Each model received the same prompt:
@tredict Please determine my current Functional Threshold Power (60-min power) for running. To do so, look at the time series of yesterday's run, especially power output and heart rate. It contains 3 threshold intervals that were deliberately held back, not at full effort. Use my configured HRmax in the capacities as my upper heart rate bound and extrapolate to estimate true threshold power. For more information, also look at the last 2 weeks of my training.
The results
| Model (LLM) | FTP estimate (60 min) | Chat transcript | |
|---|---|---|---|
| Claude.ai - Opus 4.6 | 220-225 W LLM recommendation: Can be set to 225 W |
Open | ✓ |
| ChatGPT - GPT-5.4 with Go | ~225 W | Open | ✓ |
| Perplexity - Kimi K2.6 | 218-225 W LLM recommendation: Should be set to 225 W |
Open | ✓ |
| Perplexity - Sonar 2 | ~230 W LLM recommendation: Set to at least 225 W |
Open | ✓ |
| Perplexity - Gemini 3.1 Pro Thinking | 232-235 W | Open | ✗ |
| Claude.ai - Sonnet 4.6 | 235-245 W LLM recommendation: Should be set to 235 W |
Open | ✗ |
Pretty cool, isn't it! Most models determined the FTP at around 225 watts, exactly where my own gut estimate landed.
My take on it
Now here's a personal opinion on FTP that might ruffle a few feathers. You cannot determine FTP down to the exact watt. FTP depends on so many factors (day-to-day form, sleep, nutrition, temperature and terrain) that a range is the only honest answer. Say 220-230 watts. That averages out to 225 watts. You've got to work with something during training.
I think most models did a solid job! Though with Gemini 3.1 Pro and Sonnet 4.6 as negative outliers, where the estimated FTP was a bit high. The one that surprised me most negatively was Sonnet 4.6. Or were those perhaps the models that got it right? No, I don't think so. ;-)
The most positive surprise was ChatGPT with GPT-5.4 with its brief but punchy reasoning, straight to the point. And Kimi K2.6 on Perplexity impressed me with clean, mathematically traceable reasoning as well.
How the models went about it
All models retrieved the training data via the Tredict MCP server: the time series from yesterday's run (power and heart rate in 10-second intervals), my configured capacity values (HRmax: 197 bpm, HRlth: 172 bpm) and the training history from the last two weeks. They then each performed their analysis on this data. The fundamental approach was remarkably similar across nearly all models:
1. Identify the intervals. All models correctly identified the three threshold intervals in the time series and extracted the average power and heart rate for each. Depending on the model, the values were roughly 202-204 W (interval 1), 213-216 W (interval 2) and 219-221 W (interval 3).
2. Model the heart rate-power relationship. Most models ran a linear regression across the three interval data points to quantify the relationship between heart rate and power.
3. Extrapolate to lactate threshold. Here lies the crucial step: at what power would I reach my configured lactate threshold heart rate (172 bpm)? The third interval was already almost exactly at threshold at 173 bpm and roughly 220 W, and since the intervals were deliberately held back, the models applied a small upward correction of 2-6%. How to determine your personal lactate threshold value without any AI is explained in detail in the article Automatic determination of Lactate Threshold, FTP and FTPa. And as an additional test, I asked Kimi K2.6 whether it could calculate the lactate threshold heart rate directly from the run, and Kimi came up with 170-172 bpm. Exactly what I have configured in Tredict.
ChatGPT (GPT-5.4 with Go)
ChatGPT created a tabular heart rate-power mapping from the cleanest sections of the intervals. At the lactate threshold heart rate of ~172 bpm, the observed power was 210-220 W. With an upward correction of 3-6% for the held-back effort, ChatGPT arrived at 221-228 W and settled on ~225 W. The result was additionally cross-referenced with the last two training weeks: no maximal efforts, but the previous FTP of 210 W was clearly outdated.
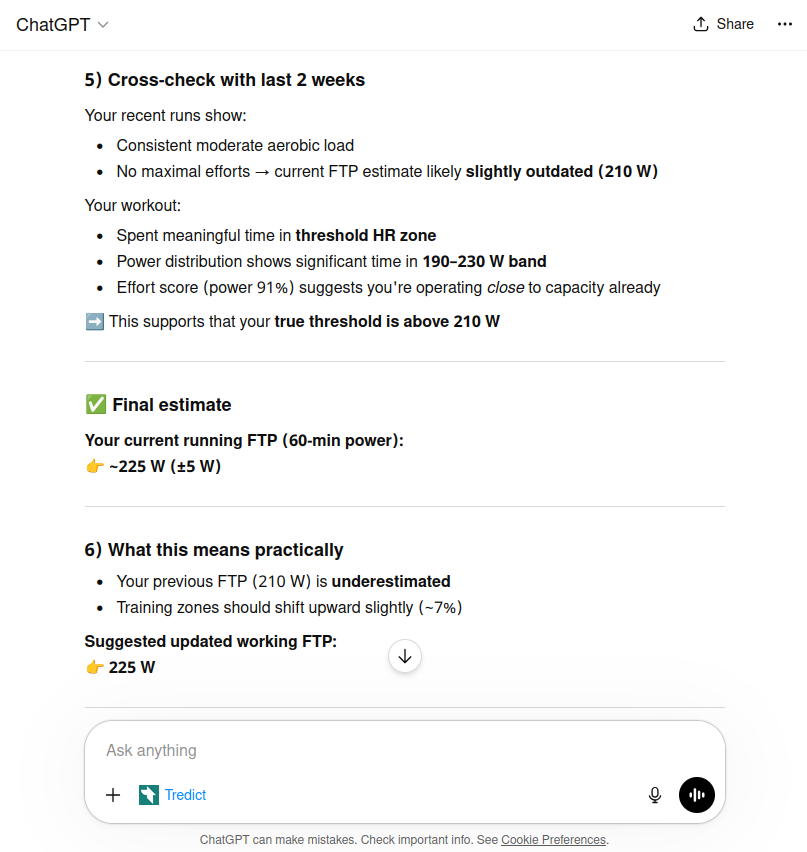
ChatGPT (GPT-5.4) determines the FTP at ~225 W and recommends adjusting the training zones.
Claude Opus 4.6
Opus 4.6 retrieved the capacity values, activity details and training history in parallel, then programmatically analysed the 10-second time series. The three intervals showed: 204 W at 81% HRmax, 216 W at 85% and 220 W at 88%. From this, a linear regression was calculated (P = 1.21 x HR + 11.3), which at the lactate threshold of 172 bpm yielded exactly 220 W. With a 2-3% upward correction for the held-back effort, Opus recommends 220-225 W. Particularly nice was that Claude built an interactive visualisation from the data, complete with regression line and interval overview.
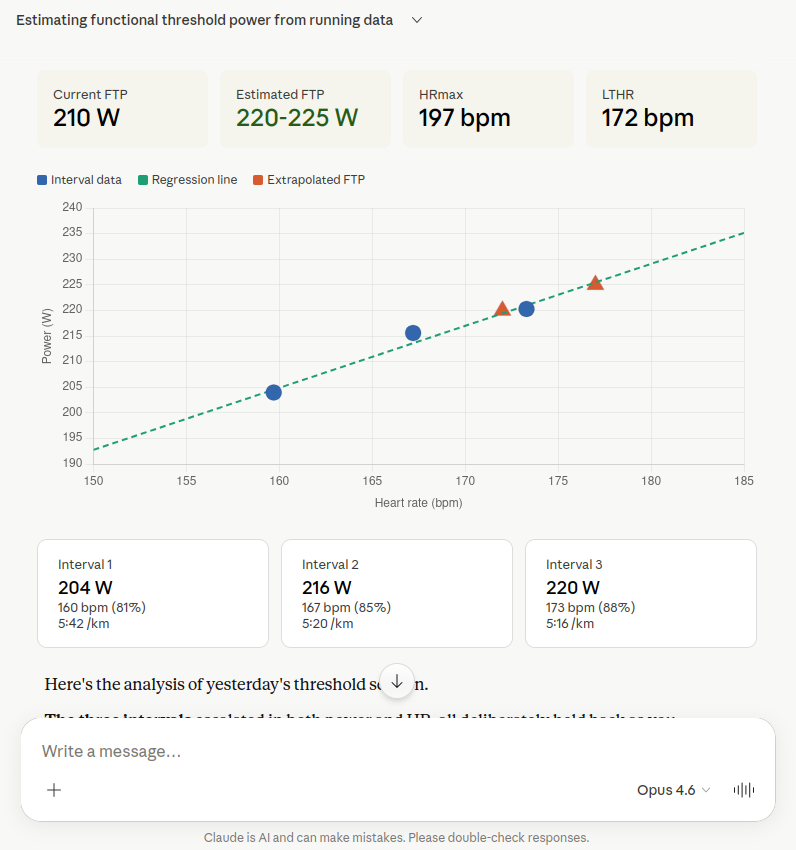
Claude Opus 4.6 creates an interactive visualisation with regression line and determines the FTP at 220-225 W.
Kimi K2.6 (on Perplexity)
Kimi K2.6 took the mathematically cleanest route. The three intervals were precisely extracted with time ranges and the cardiac drift quantified: heart rate rose by +12.8 bpm across the three intervals whilst power increased by only +17 W, typical of deliberately controlled efforts. The linear regression (HR = 0.731 x Power + 10.26) yielded a power of (172 - 10.26) / 0.731 = 221 W at the lactate threshold of 172 bpm. Kimi recommends a range of 218-225 W and notes that the old FTP of 210 W is roughly 5% too low.

Kimi K2.6 calculates the FTP mathematically cleanly via linear regression at ~221 W (218-225 W).
Sonar 2 and Gemini 3.1 Pro Thinking (on Perplexity)
Sonar 2 came in at ~230 W and advised setting the FTP to at least 225 W. Gemini 3.1 Pro Thinking extrapolated the furthest upwards at 232-235 W. Both models retrieved the same training data via the Tredict MCP server but applied more aggressive upward corrections. The full chat transcripts are linked in the table above.
Claude Sonnet 4.6, the outlier
Sonnet 4.6 is the most pronounced upward outlier at 235-245 W. Sonnet identified the same three intervals (203 W / 156 bpm, 216 W / 167 bpm, 221 W / 173 bpm) and calculated a linear regression with a slope of ~1.6 W/bpm. Unlike the other models, however, Sonnet did not extrapolate to lactate threshold (172 bpm) but to maximum heart rate (197 bpm): +24 bpm x 1.6 = +38 W, so ~259 W at HRmax. That is a methodological error! A 6-8% deduction for 60-minute sustainability was then applied, leading to 238-243 W. As a conservative working value, Sonnet recommends 235 W. The calculation via HRmax rather than a direct extrapolation to HRlth is the reason for the higher and incorrect estimate. As consolation, Claude did at least display the time series in a chart. I'll think of that during my next 10K race when I collapse at 8 kilometres, hehe.
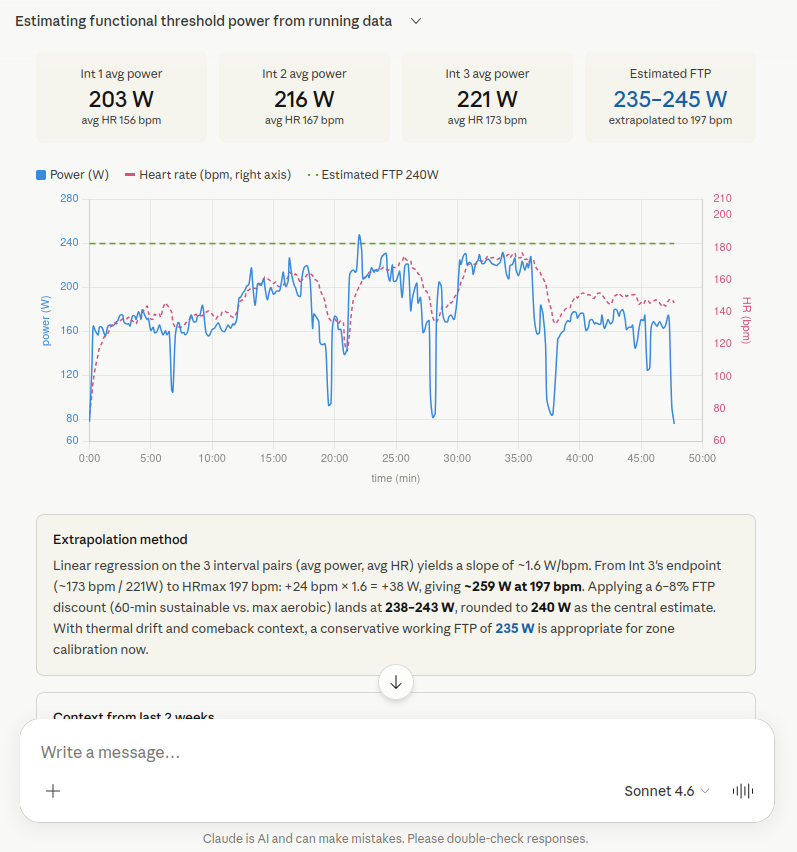
Sonnet 4.6 extrapolates to HRmax instead of HRlth and lands at 235-245 W, well above the other models. That was methodologically wrong.
Why don't all models agree?
The interval detection and linear regression were nearly identical across all models. The decisive difference lies in the final calculation step: where to extrapolate to, and which correction factors to apply. These decisions are made by the LLM based on its training data and its internal settings, such as the so-called "temperature", which controls the degree of creativity (nothing other than intentional randomness on a curve) in the response generation. Sonnet extrapolated to maximum heart rate, whilst the other models correctly extrapolated to lactate threshold. Sonnet made a methodological error in doing so. The extrapolation target is the lactate threshold heart rate, not the maximum heart rate. What we're looking for is the 60-minute power at lactate threshold, and that does not occur at HRmax. That is the reason for the significantly overestimated value.
The advantage over a pure algorithm is that the models show their working. You can read how the result was derived and judge for yourself whether the logic makes sense. If a value seems too high or too low, you can immediately see why in the reasoning and ask targeted follow-up questions in the same chat. This doesn't require expert knowledge, but a certain degree of training experience to recognise whether an FTP value is realistic or not. So I can't necessarily recommend this method for the complete beginner. On the other hand, you don't know until you try!
Precise prompting and follow-up questions
The prompt was deliberately detailed. The more precise the instruction, the better the result. And if a model doesn't understand the task properly or delivers a dubious result, you can simply ask follow-up questions and correct course. Some models then "rethink" their approach and arrive at the right result after all. In Sonnet's case, the prompt was probably still too imprecise, and one could have prompted further.
Conclusion
Eight years of running with power have given me a feel for my FTP that appears to be rather well calibrated, and the AI models confirm that. Four out of six models landed in a range of 218-230 W, exactly where my own estimate of 225 W sits. Two models came in higher at 232-245 W, but the transparent reasoning immediately shows why, be it more aggressive correction factors in Gemini's case or a methodological error in the extrapolation target in Sonnet's case.
What particularly impressed me is that the models don't simply output a number but present their reasoning transparently, from identifying intervals to calculating regressions and justifying correction factors. That makes the results traceable and verifiable. Anyone with some experience in power-based training can critically evaluate and contextualise the models' analysis. And that is exactly how AI-generated results should be treated. Don't blindly adopt them, but read the reasoning, question the result and course-correct in the chat when needed.
Connect Tredict with AI and sports watches
All six AI models in this test retrieved the training data via the Tredict MCP server. The MCP server is the interface that enables AI assistants like Claude, ChatGPT, Mistral Le Chat or models on Perplexity to access your training history, determine capacity values and even create training plans directly in Tredict.
For ChatGPT there is also the official Tredict ChatGPT app, which can be connected in just a few clicks with a free ChatGPT account:
Go to the official Tredict ChatGPT app
More about the Tredict MCP server and how to connect it with your AI assistant can be found here:
Use AI assistants and LLMs with the Tredict MCP server
On the other side, Tredict connects your sports watches and training devices fully automatically: Garmin, Coros, Suunto, Wahoo, Polar, Concept2, icTrainer and Watchletic (Apple Watch) sync your completed workouts with Tredict and can execute structured workouts directly on the watch. That closes the loop, from sports watch to Tredict to AI assistant and back.

Felix Gertz
Felix is the creator and developer of the endurance sports training platform Tredict. Since 2020, Tredict has been valued as a platform for training analysis and training planning by endurance athletes and coaches around the world.